在日常管理中,一条流水线可以执行多个场景,比如发布同一系统的不同的版本,但当不同的版本存在少量差异时,希望跳过流水线中的某些步骤不执行,则可以通过流水线条件判断来处理,具体查看如下使用说明。
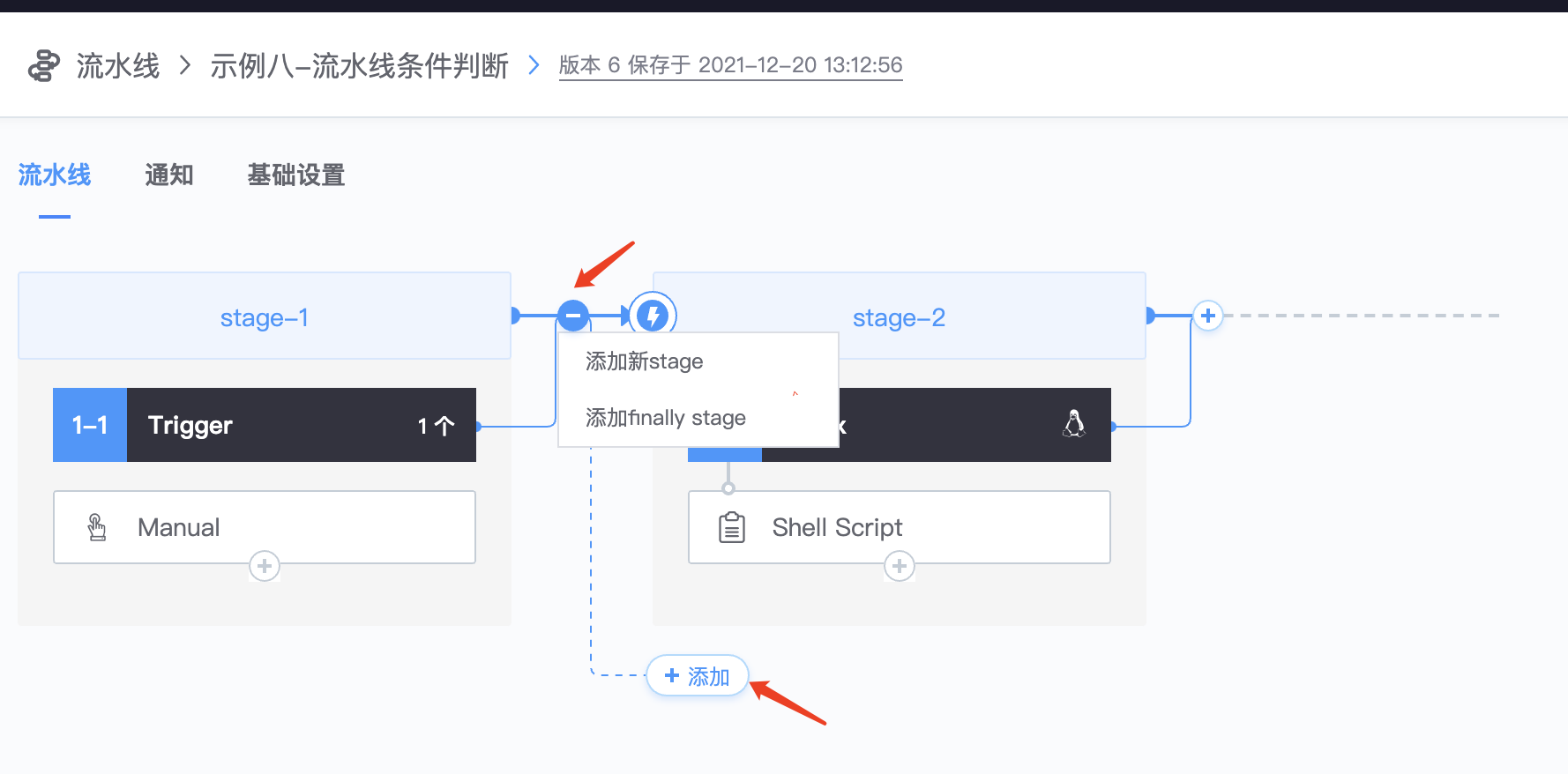
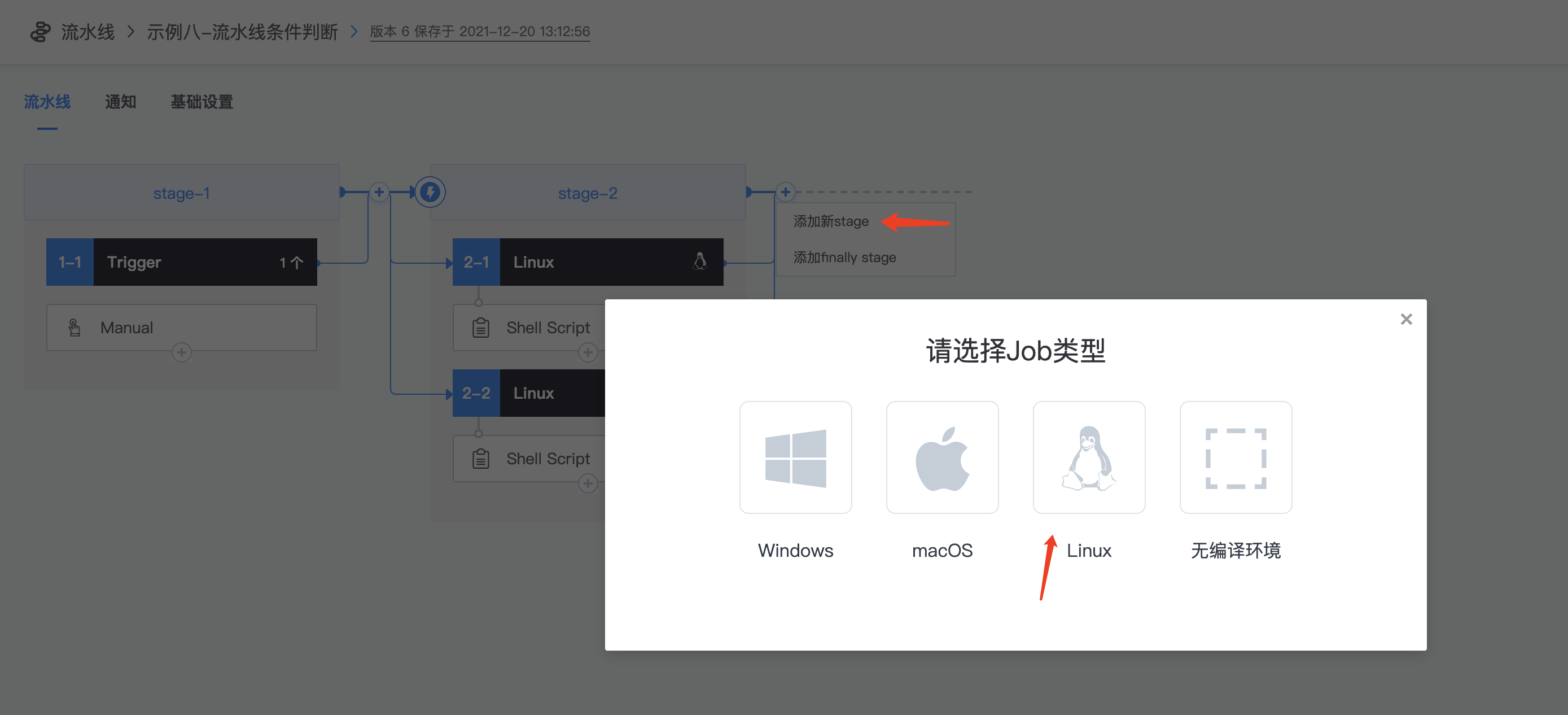
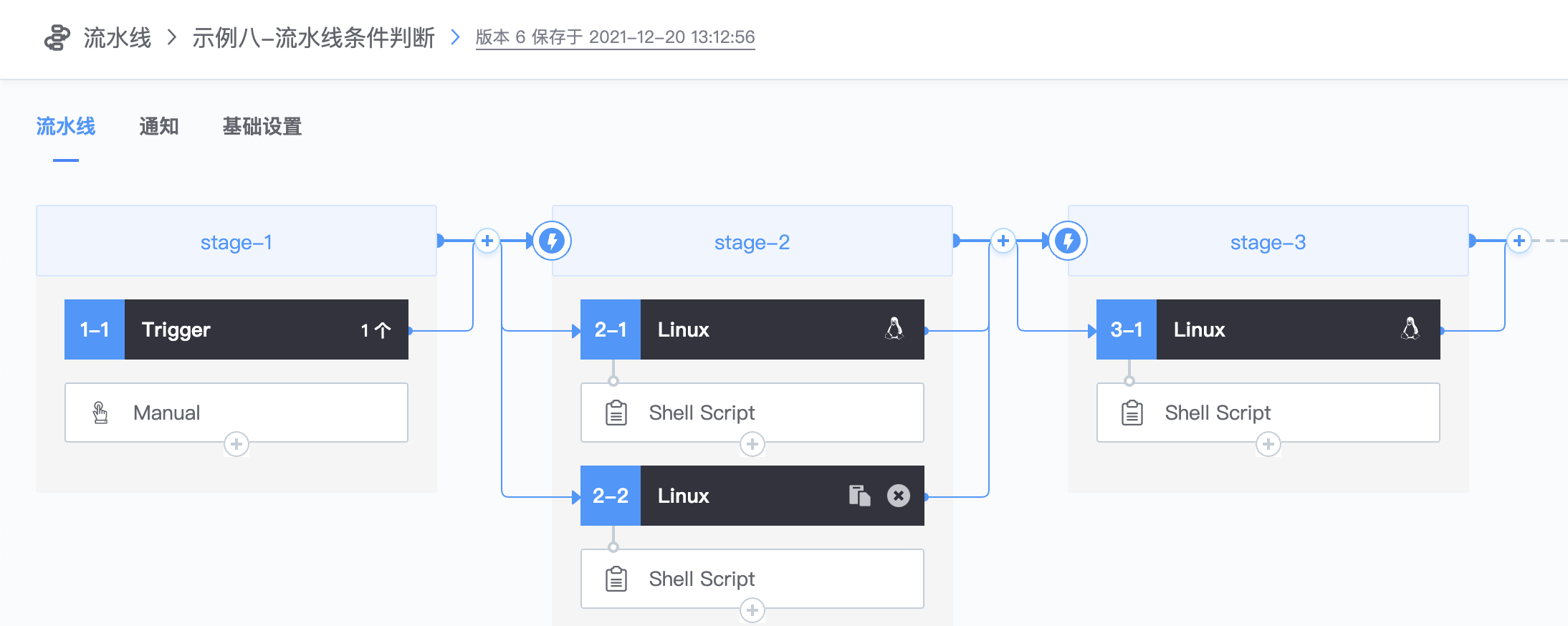
1.新建多个stage
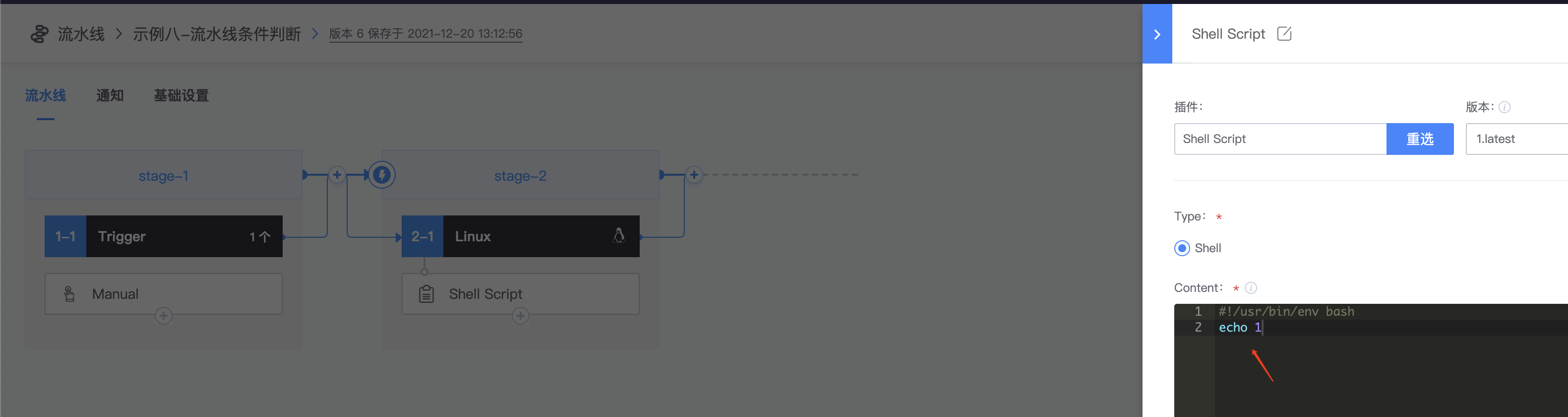
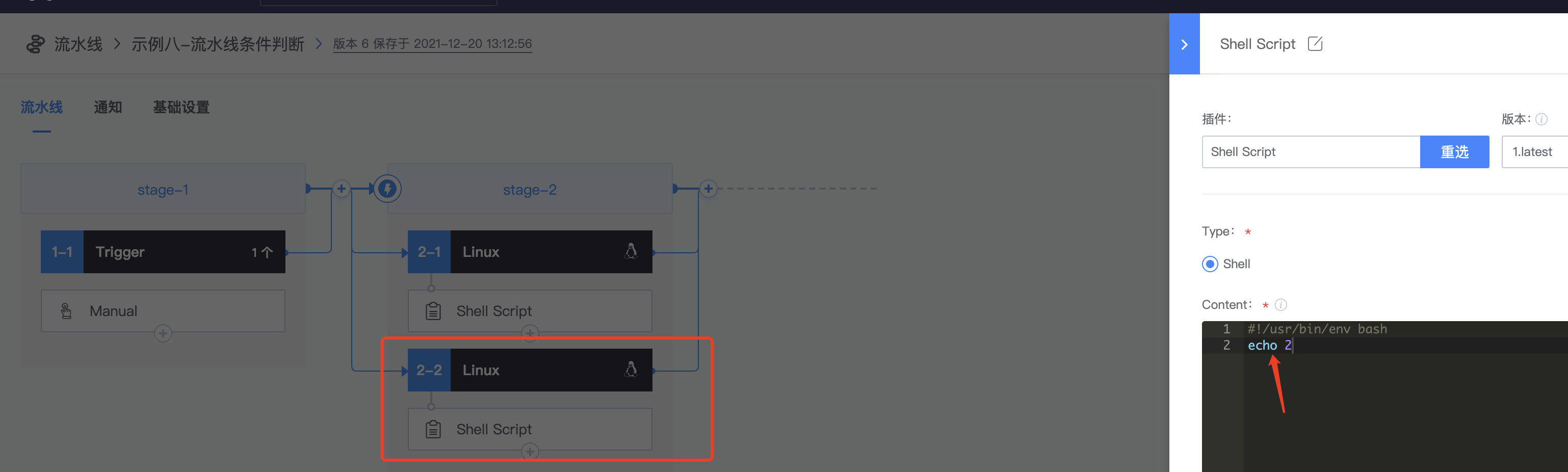
2.添加shell script插件,随便输入脚本:echo 1
3.再添加一个并行的stage
4.后面新加一个stage
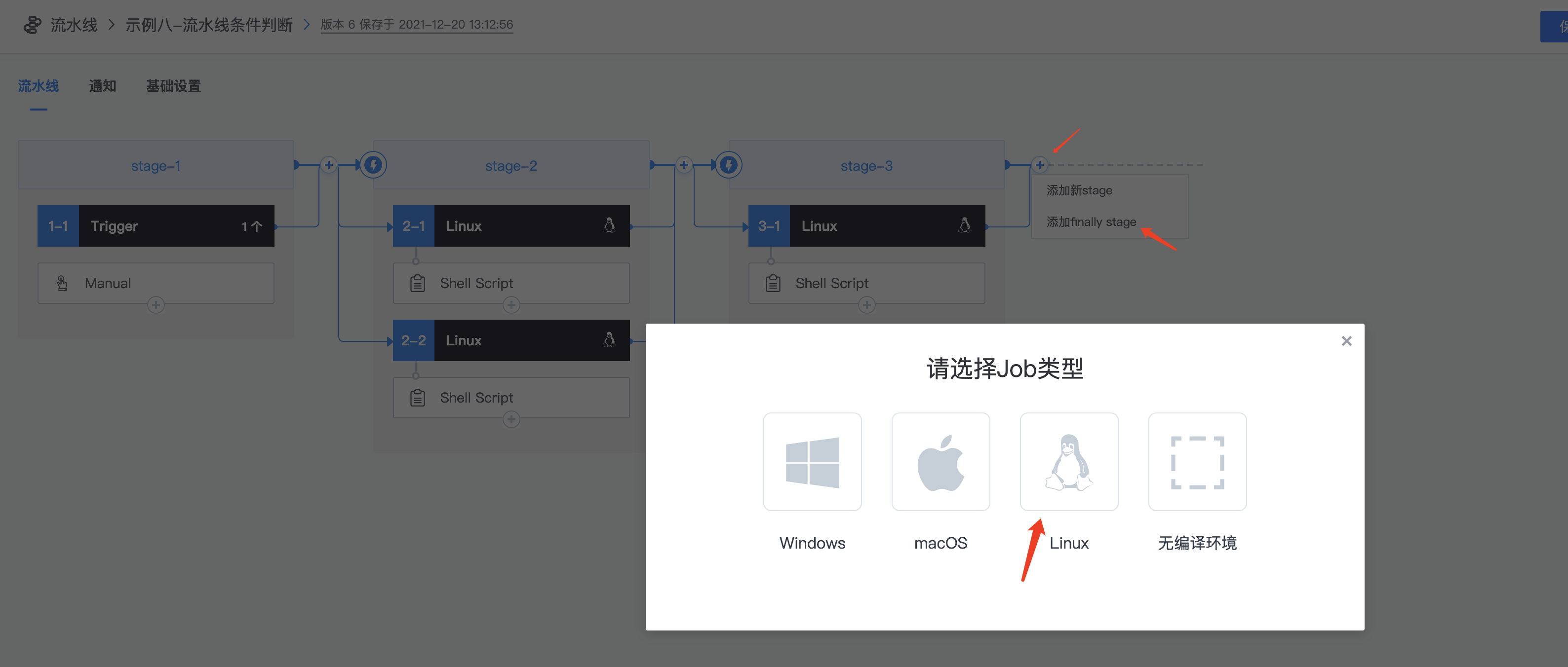
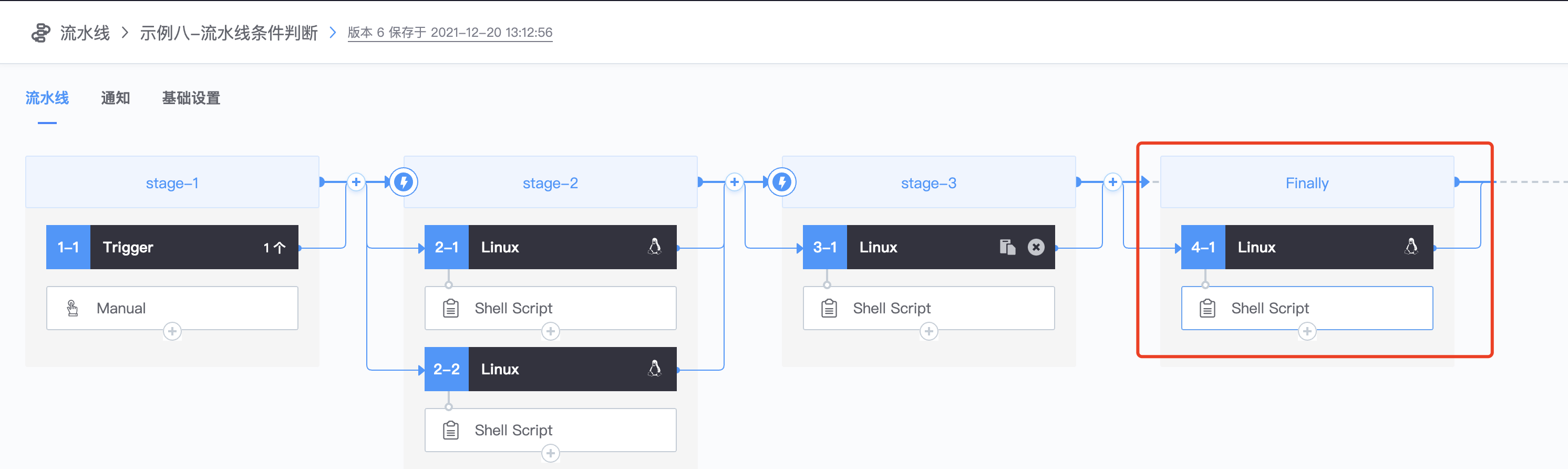
5.添加finally stage Finally stage: 流水线执行的最后一步,无论流水线执行失败还是成功,都会执行finally stage定义的步骤
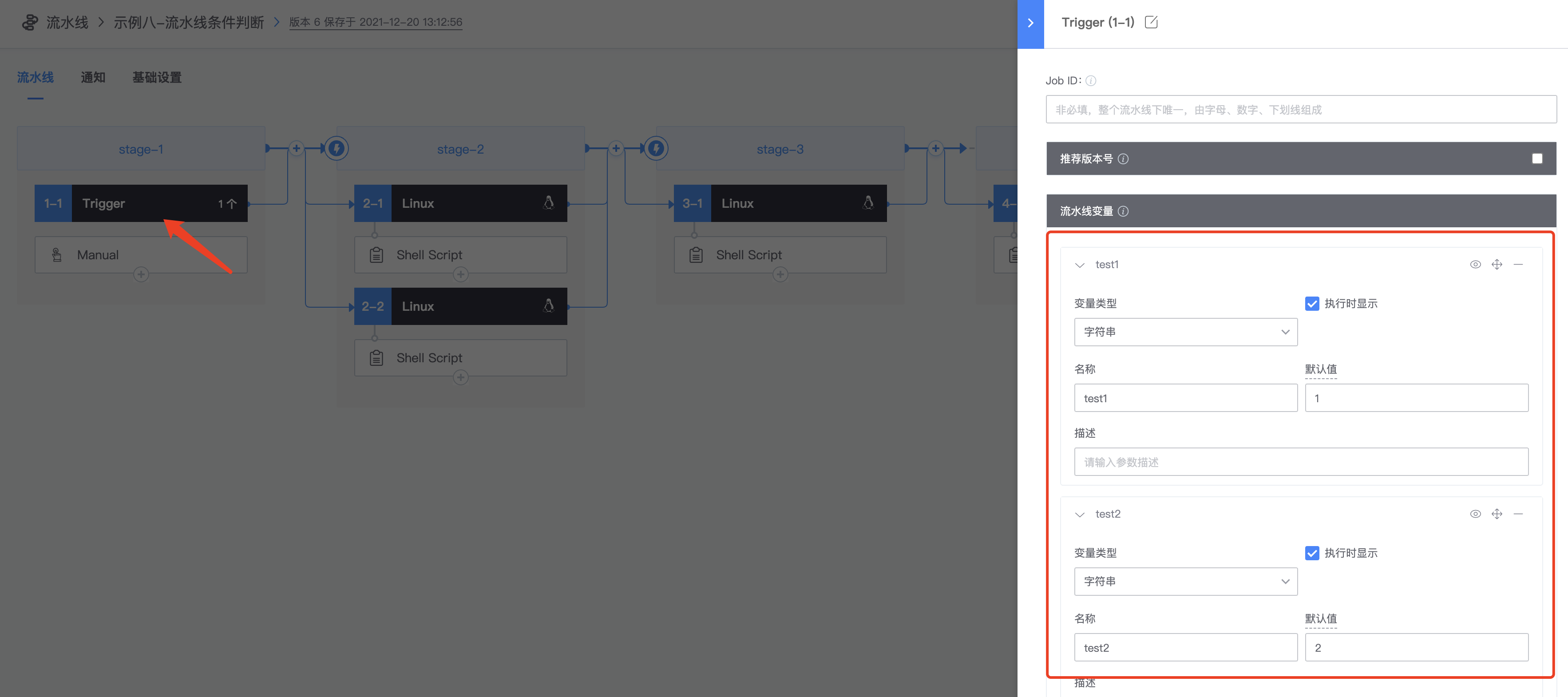
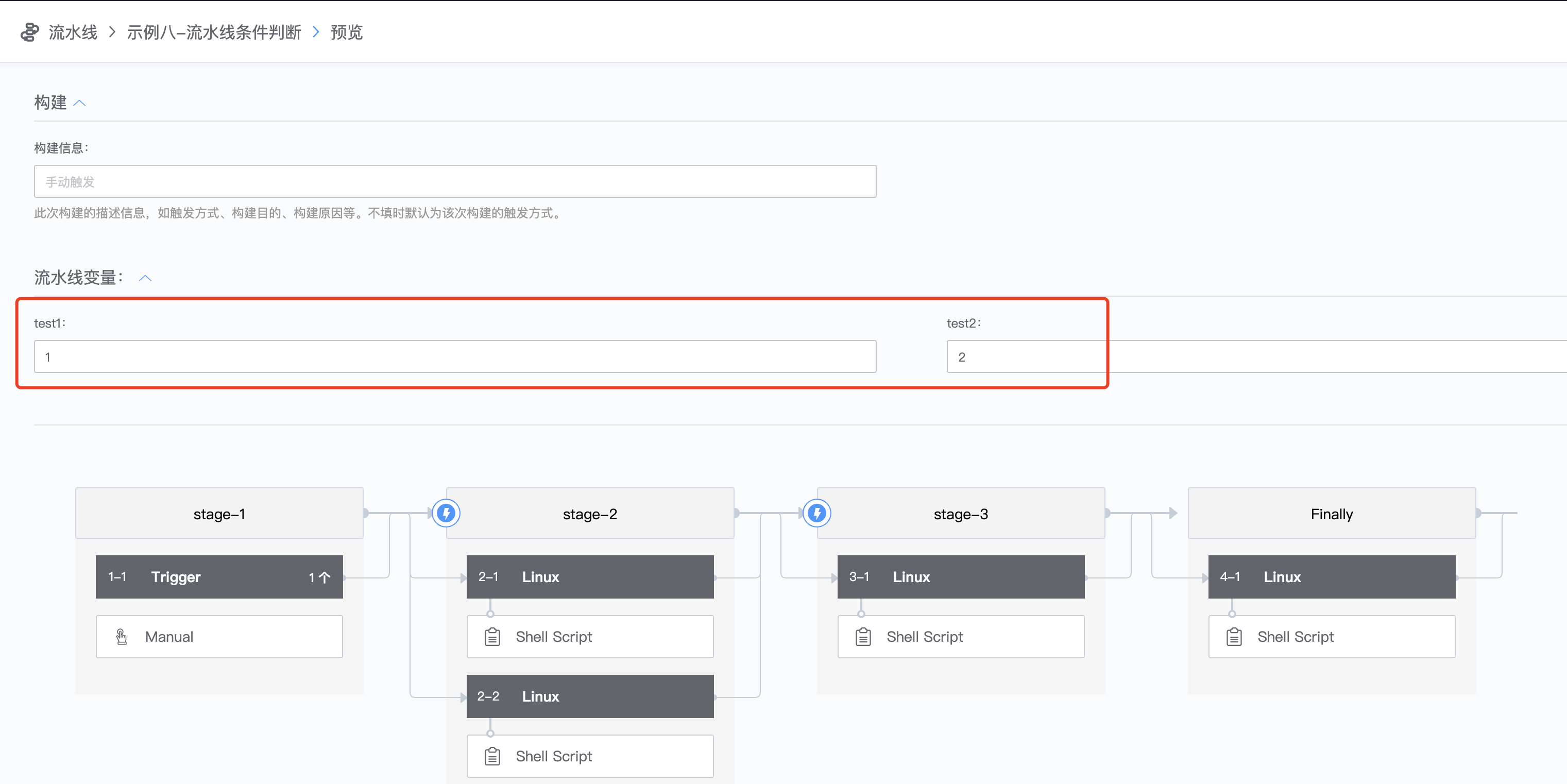
1.定义流水线变量,点击trigger,定义test1和test2两个变量
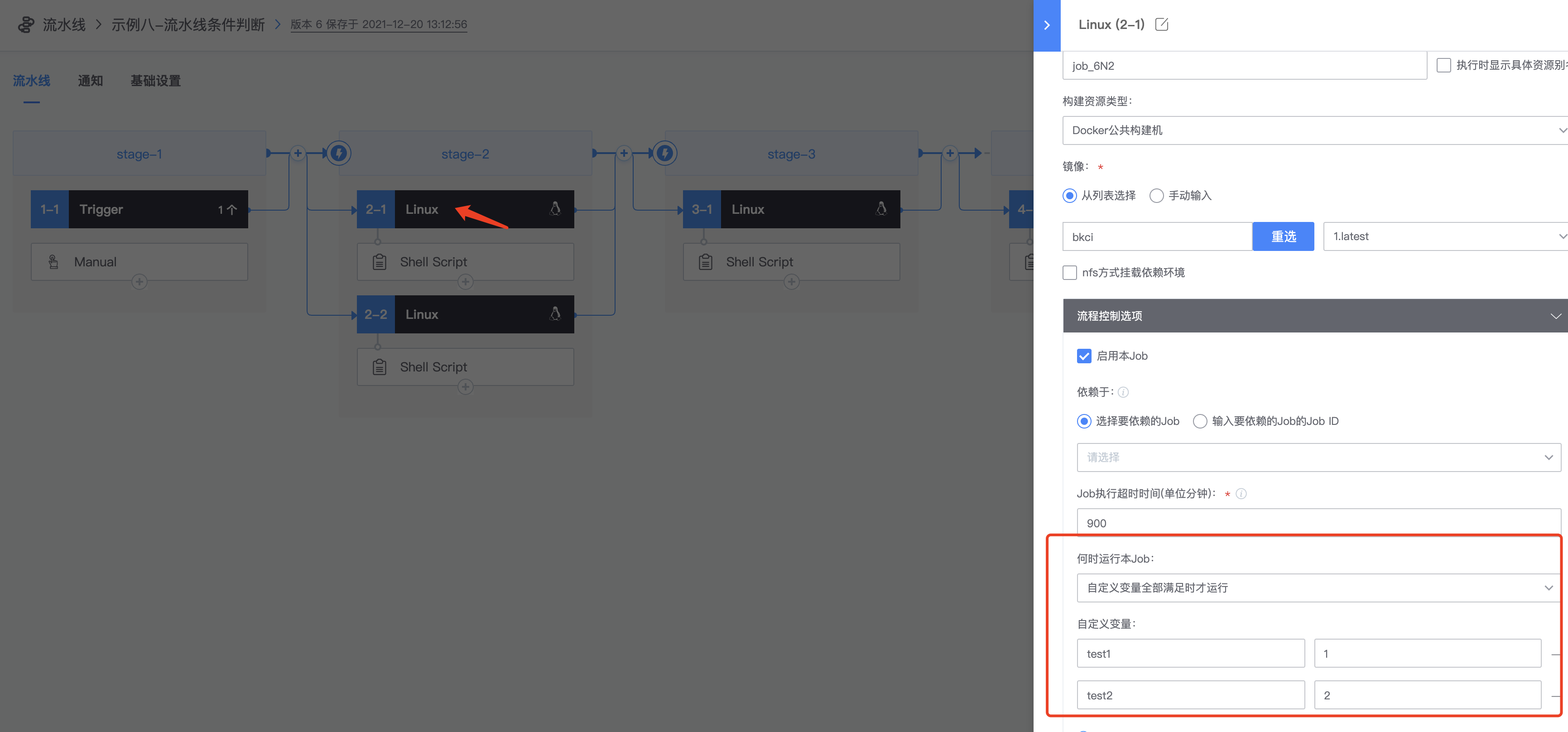
2.配置2-1的Job,选择【自定义变量全部满足时才运行】,输入刚刚自定义的两个变量test1、test2,变量值与trigger定义的值相同
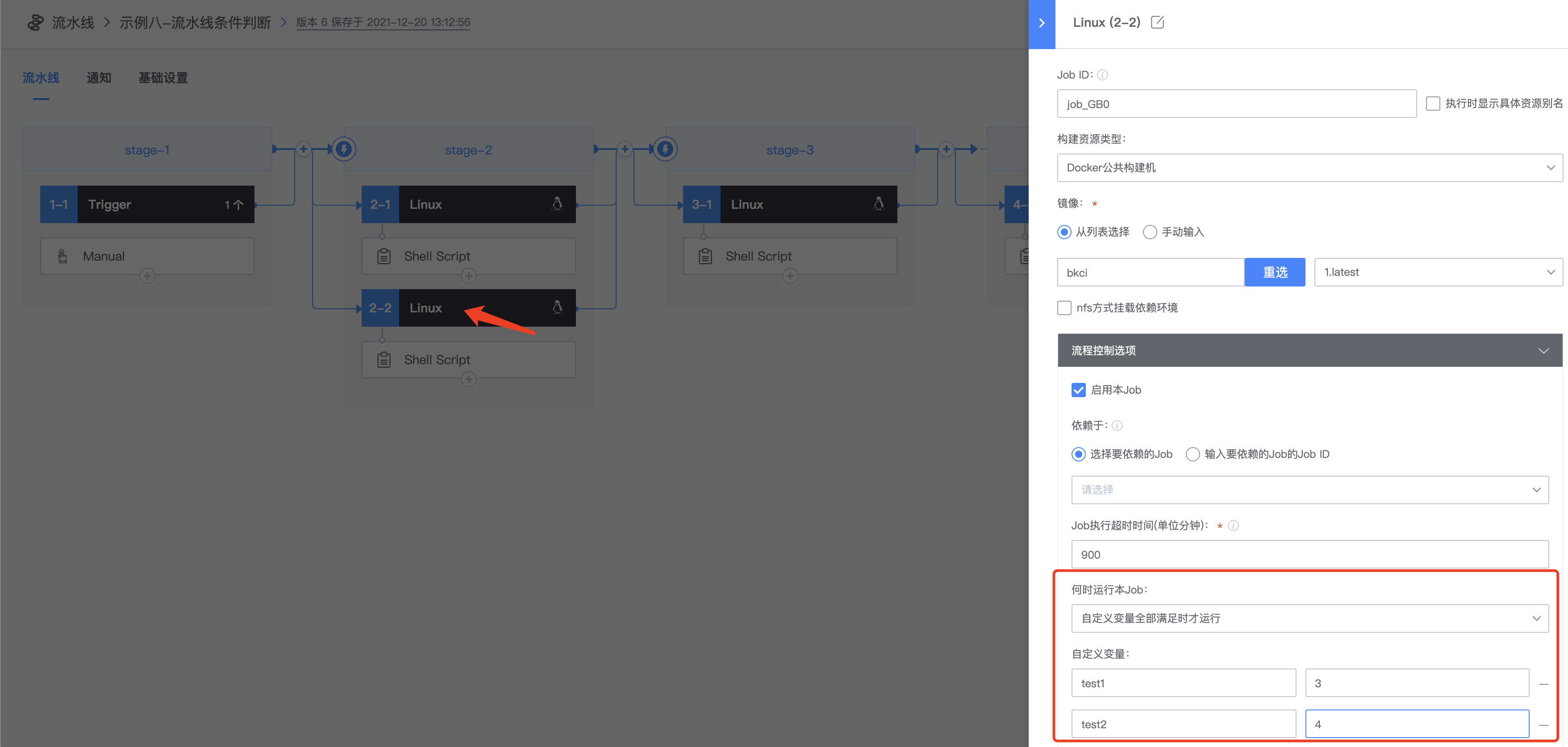
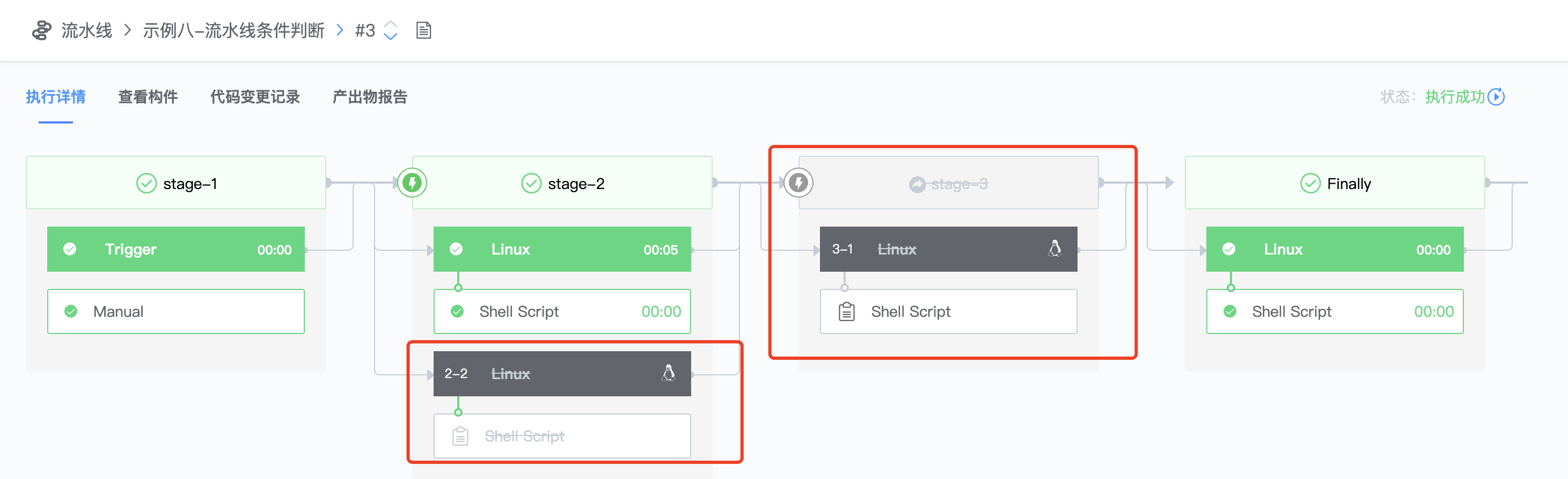
3.配置2-2的Job,点击2-2 Linux,选择【自定义变量全部满足时才运行】,输入刚刚自定义的两个变量test1、test2,值随便写,与刚刚trigger定义的值不同即可
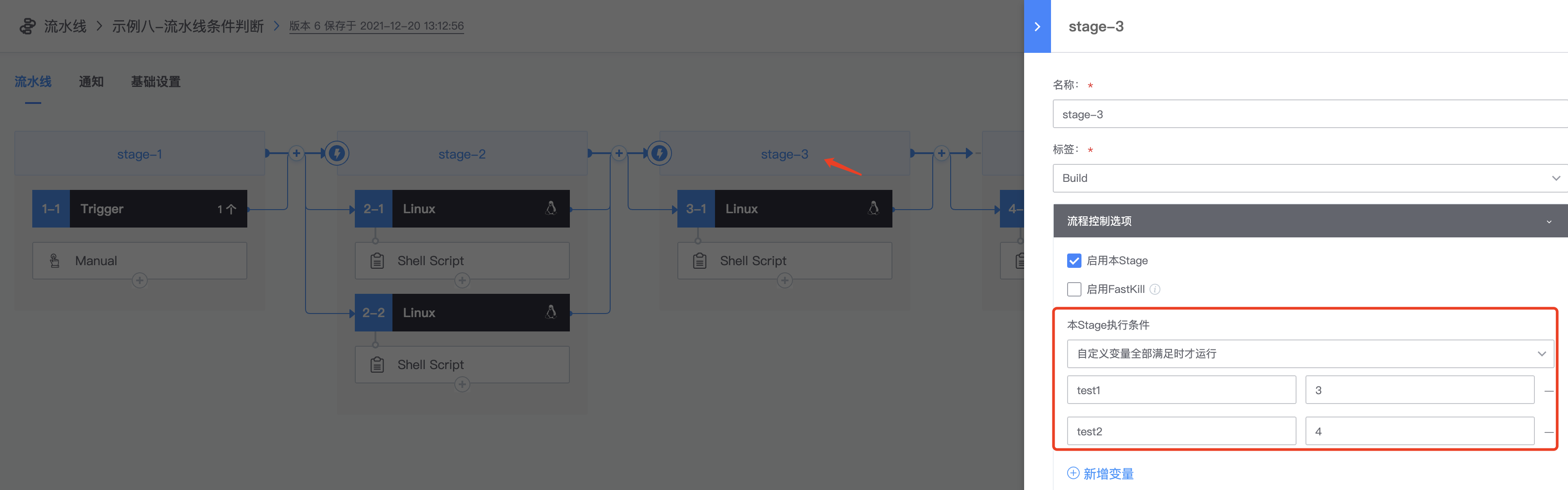
4.配置3-1 stage,选择【自定义变量全部满足时才运行】,输入刚刚自定义的两个变量test1、test2,值随便写,与刚刚trigger定义的值不同即可
5.执行流水线,test1和test2变量值保持默认 6.查看执行结果,可以看到2-2Job和stage3因为变量条件不满足,直接跳过不执行
|